Creating User-Defined Aggregates
You can create user-defined aggregates (UDAs) for use cases that fall outside of those covered by system-defined aggregates.
Prerequisites
Before defining UDAs for your models, you should familiarize yourself with the following sections:
- When to Define Your Own Aggregate Tables
- Partitioned User-Defined Aggregates
- About Incremental Rebuilds
If your aggregate definition will use one or more joins to dimensional datasets and the aggregate is allowed to be built with incremental builds, do the following before creating the UDA:
- To ensure you're aware of the special considerations for such aggregates, read the section Incremental rebuilds of aggregates that use joins in About Incremental Rebuilds.
- In Design Center, edit the fact dataset to enable the Allow incremental builds option. For more information, see Configuring Incremental Aggregate Rebuilds.
- Edit the datasets that the dimensions are based on to enable the Immutable option. This tells AtScale that the dimensions based on the dataset rarely (if ever) change, and are therefore safe to join to aggregates that have incremental rebuilds enabled. For more information, see Configuring Incremental Aggregate Rebuilds.
If you want instances of your aggregate definition to be partitioned:
- Verify that the
tables.create.partitions.enabledandaggregates.create.partition.userDefinedAggregate.enabledglobal settings are both enabled, as described in Partitioned User-Defined Aggregates. - Set a partition key for the aggregate definition, as described in the procedure below.
Defining UDAs for a model or composite model
To define UDAs for a model or composite model:
-
In Design Center, open the model or composite model you want to define a UDA for.
-
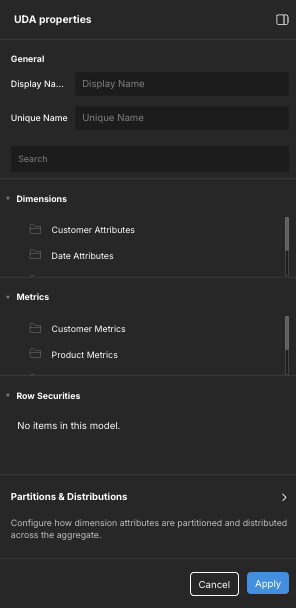
In the Model properties/Composite model properties panel, under UDAs, click the + icon. The UDA properties panel opens.
-
In the Display Name field, enter a display name for the UDA. This name will be used for the UDA in BI tools.
-
In the Unique Name field, enter a unique name for the UDA. This must be unique within the model.
-
In the Dimensions section, select the dimensional attributes to include in the UDA definition. You must select at least one.
These values are used to group the summarized metric data in the resulting aggregate table. Note that user-defined aggregate definitions are fixed: They do not include every level of a hierarchy unless they are explicitly defined.
-
(Optional) In the Metrics section, select the metrics and calculations to include in the UDA definition. This is the data that is summarized in the resulting aggregate table.
-
(Optional) In the Row Securities section, select the row security objects you want to include in the UDA definition.
-
(Optional) If you want the AtScale engine to partition instances of this UDA:
-
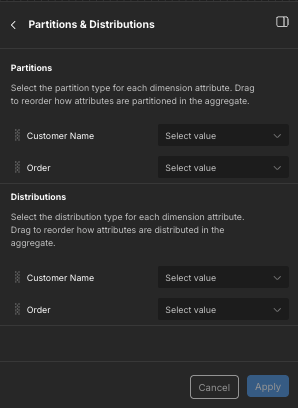
In the Partitions & Distributions section, click the arrow. The Partitions & Distributions panel opens.
-
In the Partitions section, select the partition type for each dimensional attribute in the UDA.
When the engine builds an instance of this aggregate, it creates a partition for each combination of values in the dimensional attributes. The number of partitions depends on the order of the attributes, as well as the number of values there are for each attribute. You can change the order of the attributes by clicking and dragging them in the panel.
Essentially, the partitioning key functions as a GROUP BY column. Queries against the aggregate must use this dimensional attribute in a WHERE clause. A good candidate for a partitioning key is a set of dimensional attributes that together have a few hundred to under 1000 value combinations. (The default maximum number of partitions that the AtScale engine allows is 800. You can increase the maximum, though AtScale recommends that it be set no higher than 1000.)
-
In the Distributions section, select distribution keys for the attributes as needed. As in the Partitions section, you can change the order of the dimensional attributes by clicking and dragging them in the panel.
-
Click Apply.
-
-
In the UDA properties panel, click Apply.
The UDA appears in the UDAs section of the Model properties/Composite model properties panel and is automatically added to the model's underlying SML. You can further customize the UDA via SML; for supported properties, see the AtScale SML Object Documentation on models and composite models.
Defining UDAs via SML
In addition to defining UDAs in Design Center, you can also create them by including the aggregates property in the SML file for the model or composite model:
aggregates:
- unique_name: Customer UDA
label: Customer UDA
attributes:
- name: Customer Name
dimension: Customer Dimension
metrics:
- Customer Count
Be aware that dimensions and row security objects are defined differently. Dimensions are defined using the name and dimension properties (as in the example above), while row security objects are defined with the row_security property:
aggregates:
- unique_name: Row Security UDA
label: Row Security UDA
attributes:
- row_security: Row Security Object
metrics: []
For more information on defining UDAs via SML, refer to the AtScale SML Object Documentation on models and composite models.
What to do next
The user-defined aggregate table is created the next time the model is deployed. You can check the status of the aggregate creation on the Aggregates page.