When the AtScale Engine Creates Demand-Defined Aggregates
Demand-defined aggregates are a type of system-defined aggregate that the AtScale engine creates according to various criteria, such as the history of queries against a cube and statistics about the use of existing demand-defined aggregates.
Suppose that a client application, such as Tableau, Microsoft Excel, MicroStrategy, another data-analysis tool, or even your own custom application, issues a query against a cube that was designed in and published from the AtScale Design Center.
The AtScale engine parses the query, noting the measures and dimensions that are included in it. The engine can then find out whether an aggregate table exists that will satisfy the query. There are two possible outcomes of this search: an appropriate aggregate table does or does not exist.
When an appropriate aggregate table does not exist
When a query requests aggregated data and no aggregate table yet exists that can satisfy the query, the AtScale engine takes four actions:
-
Runs the query against the data or passes it to an SQL-on-Hadoop engine.
- If the data warehouse is Google BigQuery, the engine runs the query itself.
- If the data warehouse is Hadoop, the engine passes the query to the configured SQL-on-Hadoop engine.
-
Adds the query to a log in which it compiles a history of the queries against the cube. The engine uses this history to refine its estimates of query patterns, an estimate that it uses when deciding which aggregate tables to define or redefine as it continuously optimizes query performance by creating new instances.
-
Determines the best aggregate-table definition or definitions to create to satisfy both the current query and similar queries in the future. The engine does this by examining the measures and dimensions in the query, the history of queries against the same cube, and statistics for the cube. A candidate definition could therefore contain measures that the current query does not reference.
Example
Suppose that this query requested the count of items (measure) that were sold per customer gender (dimensional attribute) for a particular product line (dimensional attribute). The AtScale engine would include that measure and, if the cost of doing so were negligible, the engine might also include additional measures, such as the total dollar sales amount of the sales and the number of sales transactions.With very little up-front cost, a new aggregate table based on this definition could satisfy not only the current query but possible future queries against these other measures.
The AtScale engine does not include measures from more than one fact dataset when creating a definition. If a query references measures that are in two fact datasets, the AtScale engine considers whether to create two definitions, one for the measures in one dataset and another for the measures in the other dataset.
-
Determines whether the cardinality of an instance of an aggregate-table definition would be less than or equal to the limit set by the compression factor. This factor specifies the ratio of the cardinality of the fact dataset to the cardinality of the instance. By default, the ratio is 3 to 1, which means that the AtScale engine will not define an aggregate table for which an instance would have a cardinality greater than 1/3 of the cardinality of the corresponding fact dataset. Example If a fact dataset has one billion rows, an aggregate-table instance created from the proposed definition would have to contain no more than 333,333,333 rows. If the instance would have more rows than that, the AtScale engine would not define the aggregate table.
When an appropriate aggregate table does exist
When a query requests aggregated data and an aggregate table that can satisfy the query does exist, the AtScale engine:
- Examines the query in the context of the query history for the cube.
- Examines statistics for the cube.
Using the information that it gathers, the engine decides to take one of these actions:
- Create an additional aggregate-table definition.
- Supersede the existing definition that is used to satisfy the query. If the engine decided to supersede the existing definition with a new one, it could choose between narrowing the definition (removing measures, perhaps because those measures are not being used) or widening it (adding measures that the query history shows are also used from the fact dataset and aggregated by the same dimensional attributes).
- Take both of the preceding actions, creating additional aggregate-table definitions and superseding existing definitions.
The AtScale engine can use aggregate instances that contain complete degenerate dimensions to populate filters in data-analysis tools such as Tableau and Microsoft Excel. If an aggregate instance is complete for a degenerate dimension (meaning the instance contains all of the values for it), then querying the aggregate can be faster than querying the fact dataset.
For example, suppose that an aggregate instance exists that includes the complete degenerate dimension Color and the measure Order Quantity. In Tableau, adding the Color dimension to the Filters card opens the Filter dialog, which displays the colors in the dimension. Behind the scenes, the AtScale engine can query the aggregate to retrieve the values for populating the Filter dialog.
Figure 1. The Filter dialog in Tableau, displaying all of the values for the degenerate dimension Color
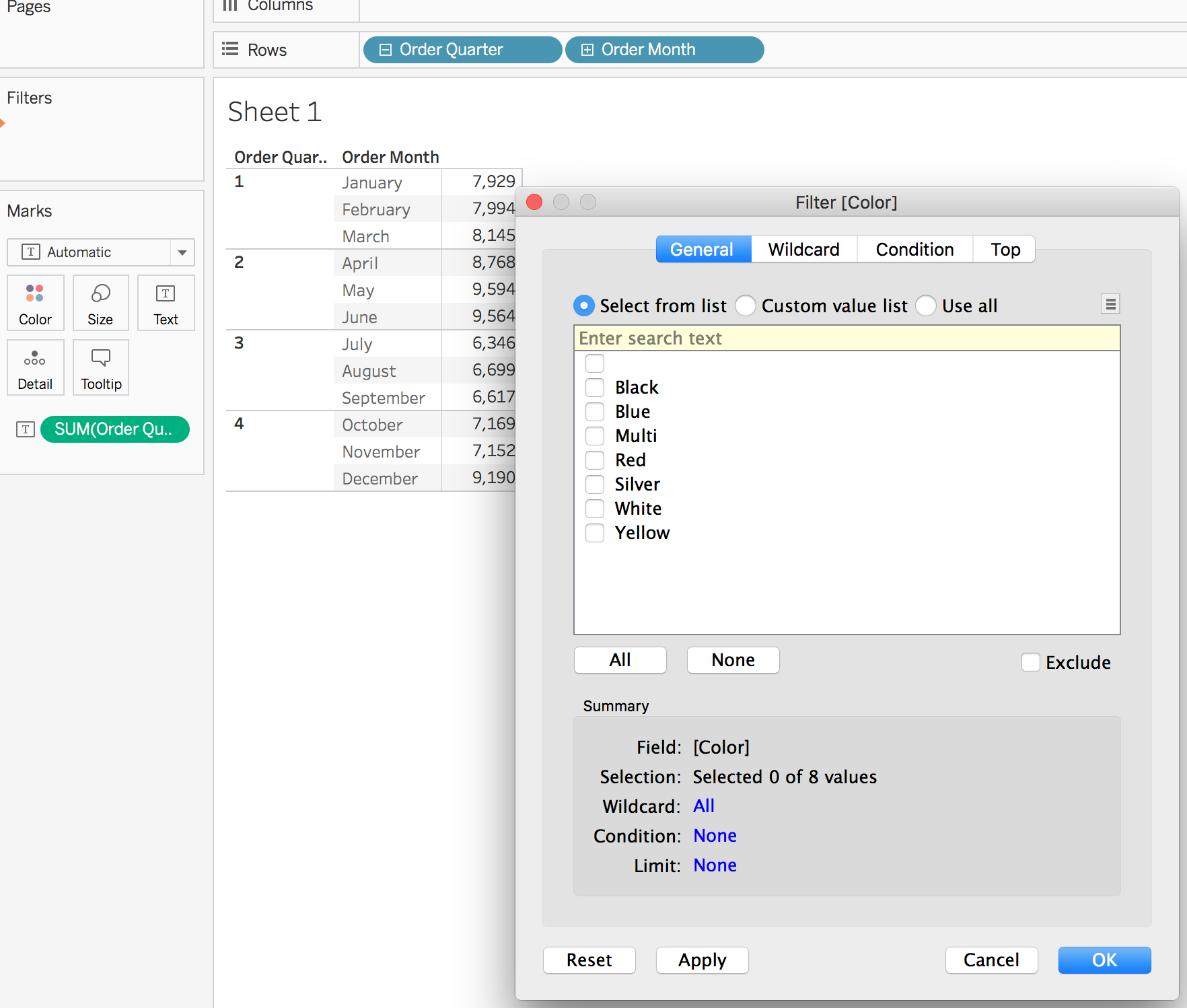
However, if an aggregate instance contains any non-degenerate dimensions, then the AtScale engine will not use it to populate filters.
More information
SQL Hints to Control the Use and Generation of Aggregate Tables